AI 칩 만드는 AI…구글, 딥 러닝으로 더 빠르고 더 작은 AI 칩 설계
설계 데이터와 성능 수치를 바탕으로 AI 칩 아키텍처를 생성
지도 학습을 사용해 주어진 가속기의 성능 예측 모델을 훈련
지연 시간을 2.7배 개선하고 다이(die) 크기를 1.5배 축소 설계

인공지능(AI)를 사용해 더 빠르고 작은 AI 칩을 설계하는 기술이 나왔다. 구글과 UC 버클리(Berkeley) 연구팀은 기존의 설계 데이터와 성능 수치를 바탕으로 AI 칩 아키텍처를 생성하는 PRIME이라는 딥 러닝 접근 방식을 개발했다고 밝혔다. 구글 블로그에 따르면 새로운 접근 방식은 구글의 EdgeTPU 가속기나 기존 도구를 사용해 만든 다른 설계보다 지연 시간이 짧고 공간이 덜 필요한 설계를 생성할 수 있다.
구글은 이 분야에 상당한 관심을 가지고 있다. 작년에 TPU 설계 중 칩의 구성요소의 레이아웃(배치)을 최적화하는데 머신 러닝을 사용했다고 밝힌 바 있다. 또한 시놉시스(Synopsys)와 케이던스(Cadence)와 같은 칩 설계 도구 제조업체도 소프트웨어 제품군에 머신 러닝을 도입하고 있다.
하드웨어 설계를 위해 이전에 설계된 가속기의 데이터를 사용하는 가장 간단한 방법은 지도 학습(supervised learning)을 사용해 입력으로 주어진 가속기의 성능 목표를 예측할 수 있는 예측 모델을 훈련하는 것이다. 그런 다음 이 학습된 모델의 성능 출력을 최적화해 새로운 가속기를 설계할 수 있다. 그러나 지도 학습 예측 모델은 실행 불가능한 가속기의 데이터에 대해 잘못된 값을 예측하도록 모델을 속이는 '적대적 예'로 학습될 수 있다.
이와 같은 문제를 해결하기 위해 PRIME은 최적화 중에 발견될 '적대적 예'에 속지 않는 강력한 예측 모델을 학습한다. 그런 다음 시뮬레이터를 설계하기 위해 표준 옵티마이저를 사용해 이 모델을 간단히 최적화할 수 있다. 더 중요한 것은 이전 방법과 달리 PRIME은 실행 불가능한 가속기의 기존 데이터를 활용해 설계 하지 말아야 할 사항을 학습할 수도 있다는 것이다.
데이터 기반 접근 방식의 주요 이점 중 하나는 대상 응용 프로그램 전반에 걸쳐 일반화되는 최적화 모델을 학습할 수 있다는 것이다. 또한 이러한 모델은 설계자가 가속기를 최적화하려고 이전에 시도한 적이 없는 새로운 응용 프로그램에 효과적일 가능성이 있다.
새로운 애플리케이션을 일반화하도록 PRIME을 훈련하기 위해 가속하려는 신경망 애플리케이션을 식별하는 컨텍스트 벡터를 조건화해 학습된 모델을 수정한다. 피드포워드 레이어 수, 컨볼루션 레이어 수, 총 매개변수 등과 같은 새로운 애플리케이션의 상위 수준 기능을 컨텍스트로 사용한다. 그런 다음 설계자가 지금까지 본 모든 애플리케이션에 대한 가속기 데이터로 단일 대형 모델을 훈련한다. PRIME의 이러한 상황별 수정을 통해 수많은 동시 애플리케이션과 예상치 못한 새로운 애플리케이션에 대해 제로샷 접근 방식으로 가속기를 최적화할 수 있다.
PRIME 접근 방식은 더 빠르고 효율적인 설계를 가능하게 하는 것 외에도 전통적인 시뮬레이션 기반 칩 설계가 시간과 계산 비용이 많이 들 수 있기 때문에 중요하다. 시뮬레이션 소프트웨어를 사용해 저전력 사용이나 짧은 지연 시간과 같은 설계 제한 사항을 충족하는 칩을 설계하면 설계가 실행 불가능한 경우가 많다.
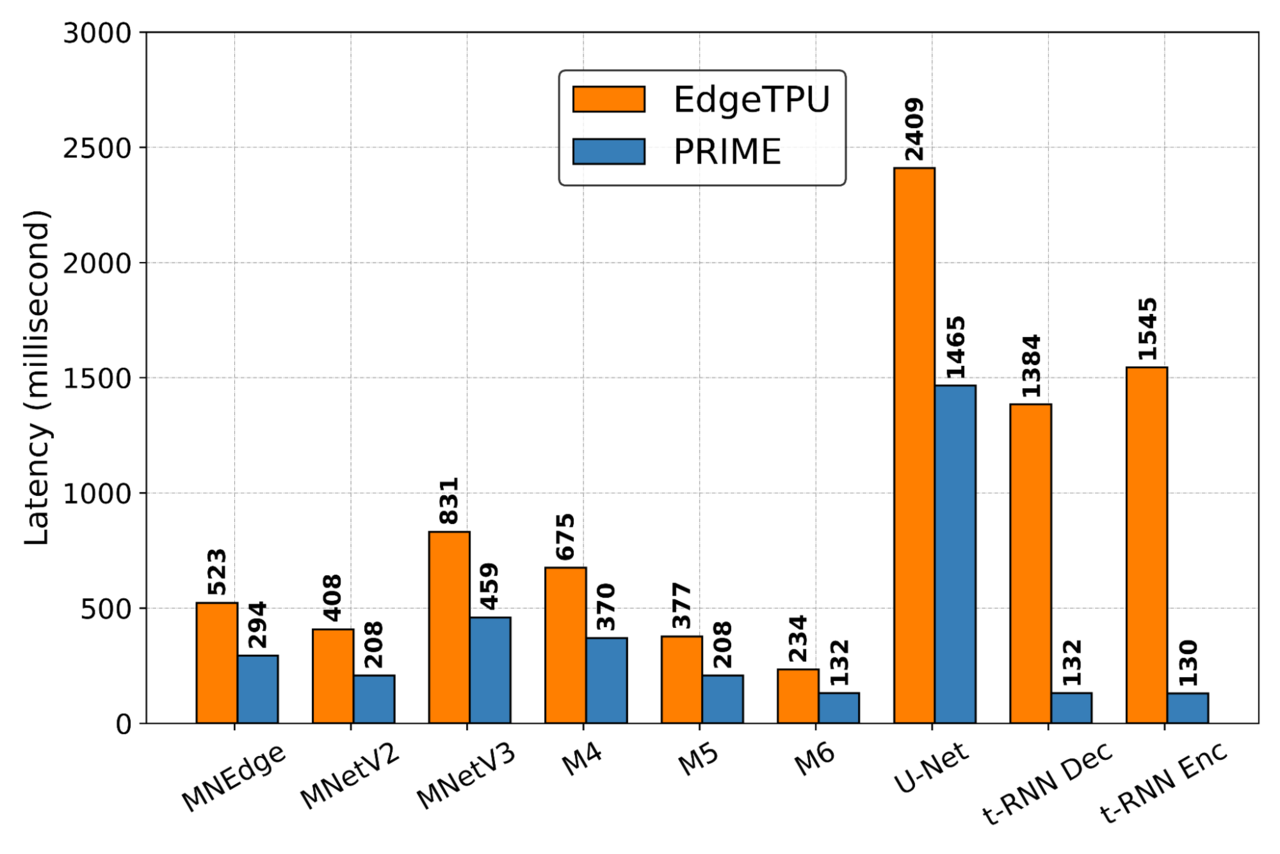
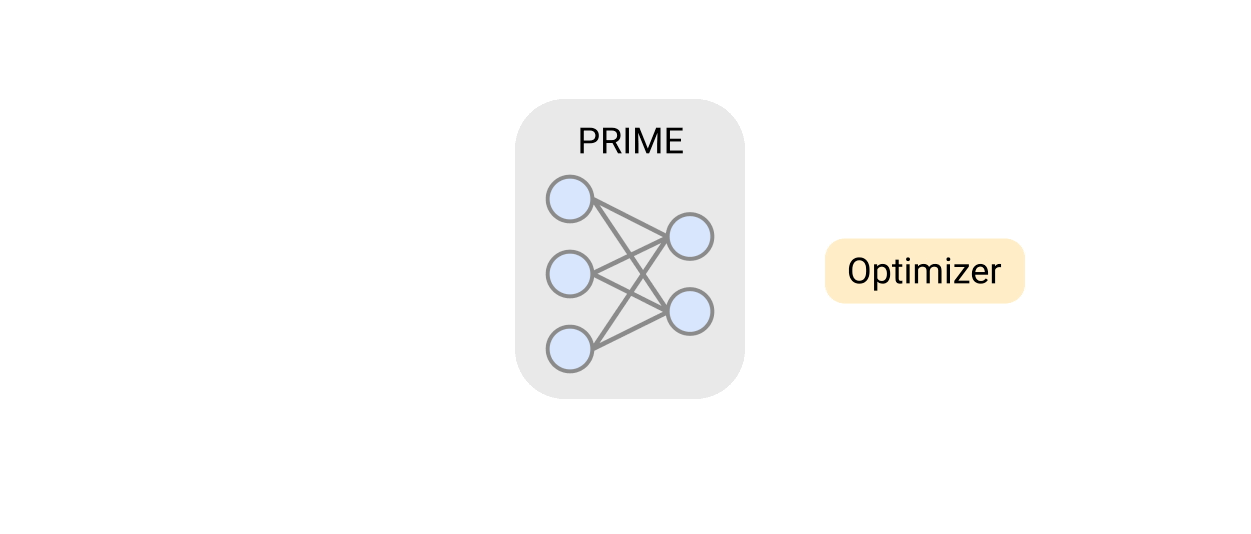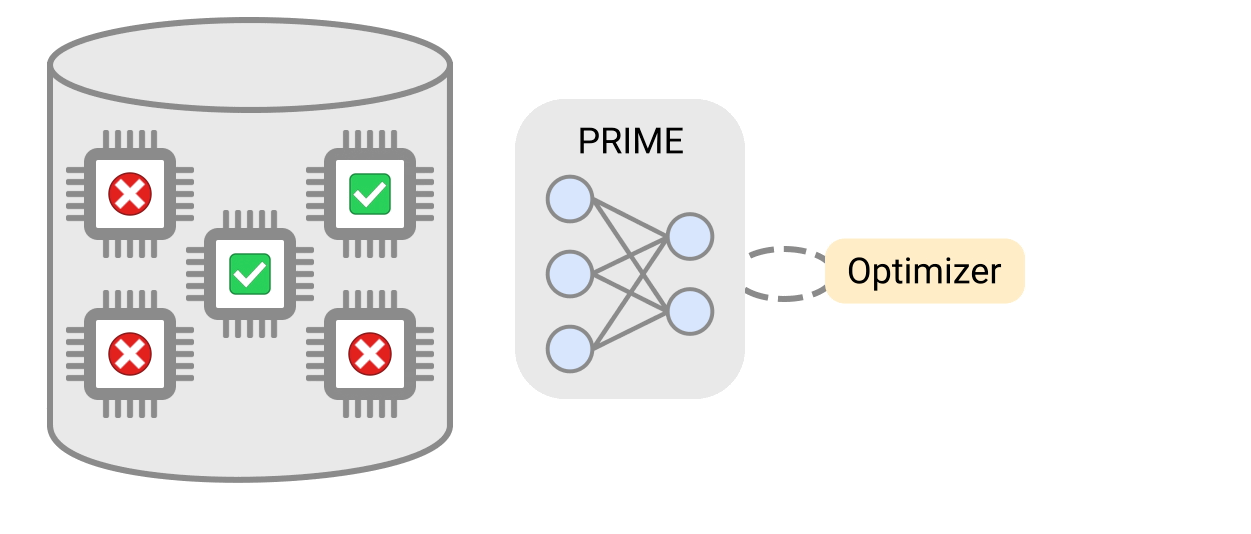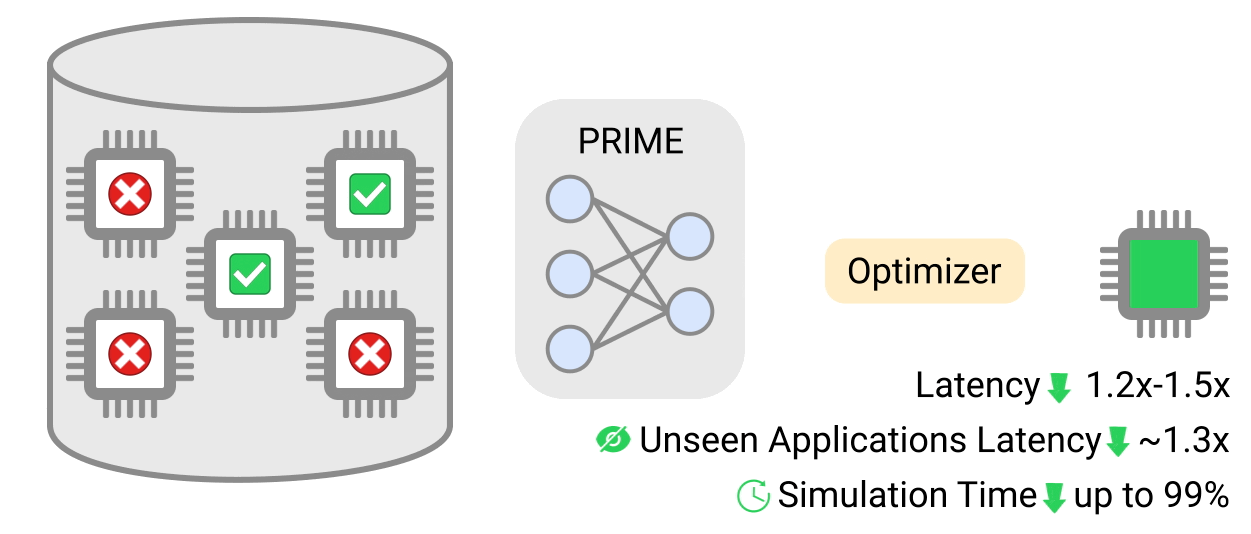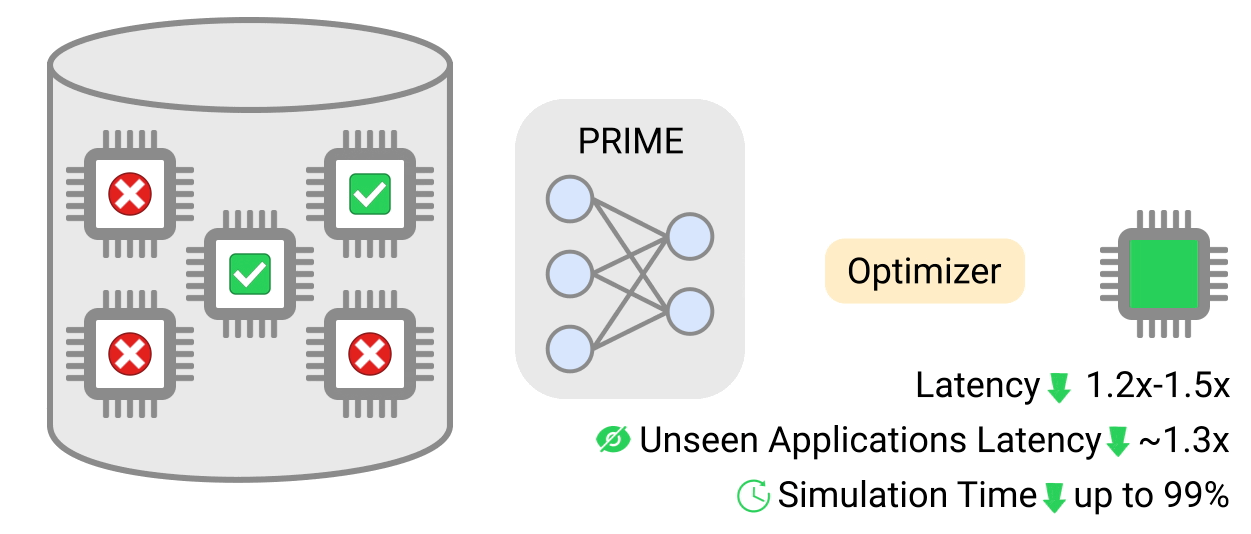
연구팀은 9개의 애플리케이션에 대해 PRIME 아키텍처로 최적화된 가속기 설계와 수동으로 최적화된 EdgeTPU 설계를 대조하여 PRIME의 성능을 평가한다. PRIME 방식으로 만든 칩 설계는 시뮬레이션 기반 방식을 사용하여 생성한 것보다 최대 50% 더 적은 지연 시간을 가지며 딥 러닝 접근 방식도 칩 아키텍처를 생성하는 데 걸리는 시간을 최대 99%까지 단축할 수 있었다.
또한 PRIME 칩 설계가 전반적으로 지연 시간을 2.7배 개선하고 다이(die) 크기를 1.5배 줄인 것을 발견했다. 다이 크기를 줄여서 칩을 더 저렴하게 만들고 전력 소비를 낮추기 위한 목적으로 PRIME을 훈련하지 않았기 때문에 다이 크기 축소는 놀라운 성과이기도 하다.
전반적으로 이 방법을 사용하면 모델을 특정 애플리케이션에 맞게 최적화할 수 있다. PRIME은 또한 데이터가 있는 모든 애플리케이션에서 설계 데이터에 대한 단일 대형 모델을 훈련함으로써 훈련 데이터가 없는 애플리케이션에 대해 최적화할 수 있다.
PRIME의 효율성은 가속기 설계 파이프라인에서 기록된 오프라인 데이터를 활용할 수 있는 가능성을 강조한다. 연구팀은 PRIME이 다양한 응용 분야에 활용 가능성을 갖고 있다고 믿는다. 여기에는 복잡한 최적화 문제를 해결해야 하는 애플리케이션을 위한 칩을 만드는 것과 하드웨어 설계를 시작하는 데 도움이 되는 훈련 데이터로 성능이 낮은 칩 아키텍처를 사용하는 것이 포함된다. 또한 범용 특성 덕분에 하드웨어-소프트웨어 공동 설계에 PRIME을 사용하기를 희망한다.
(출처:http://www.aitimes.com/news/articleView.html?idxno)
'인공지능(AI)' 카테고리의 다른 글
| AI가 졸음운전 막는다. (14) | 2022.04.08 |
|---|---|
| 농업과 축산업에 AI 도입 시급 (7) | 2022.04.02 |
| 구글, AI 검색 기술로 이용자 위기 상황 탐지 (4) | 2022.04.02 |
| 링크드인에서 AI가 만든 가짜 프로필이 넘쳐난다 (10) | 2022.04.01 |
| 위험 수위 넘은 딥페이크 기술 (9) | 2022.03.26 |
| AI가 사이버 해결사로 나선다 (4) | 2022.03.26 |
| 신음하는 지구, 최악의 가뭄…AI 기술로 대응한다 (10) | 2022.03.23 |
| AI가 사이버 해결사로 나선다 (6) | 2022.03.22 |